
¡Que Menú!
Suspendido
- Mensajes
- 55
- Puntuación de reacción
- 0
Hola ciudadanos de un lugar llamado mundo
Os traigo mi primer tutomierder que quizás os resulte útil para sacar información de otras webs y así ganar algo de $$ con el pasar de los días.
¿Que necesitamos?
- Un hosting (cuantos más recursos mejor), importante que tenga CURL activado
- Navegador Chrome
- Mínimo una web para hacer scrap
- Ganas de aprender
- Un miembro de 7cm mínimo (Esto no es 100% requerido, sino casi nadie de aquí podría hacerlo :dale2
")
El procedimiento es muy fácil una vez que le pillas el truco, a mi en mis inicios me costó bastante, pero también cabe destacar que los tutoriales que encontraba eran super raros y había que hacer millones de cosas extrañas. Este es fácil, bonito y sencillo.
Empecemos
La url a scrappear será:
Código:
http://www.cinetube.es/peliculas/comedia/ver-pelicula-torrente-5-operacion-eurovegas.htmlEn nuestro archivo php iniciamos la conexión con dicha URL y la guardamos en una variable nuestra
PHP:
// Para que se vean bien los caracteres extraños
header('Content-Type: text/html; charset=utf-8');
// Creamos la conexión con la página
$urlCT = "http://www.cinetube.es/peliculas/comedia/ver-pelicula-torrente-5-operacion-eurovegas.html";
$ch = curl_init($urlCT);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$cl = curl_exec($ch);
$dom = new DOMDocument();
@$dom->loadHTML($cl);
$xpath = new DOMXpath($dom);Ahora, con Google Chrome (puede ser otro navegador pero yo lo enseño con este) buscamos el XPATH de los elementos que queremos extraer:
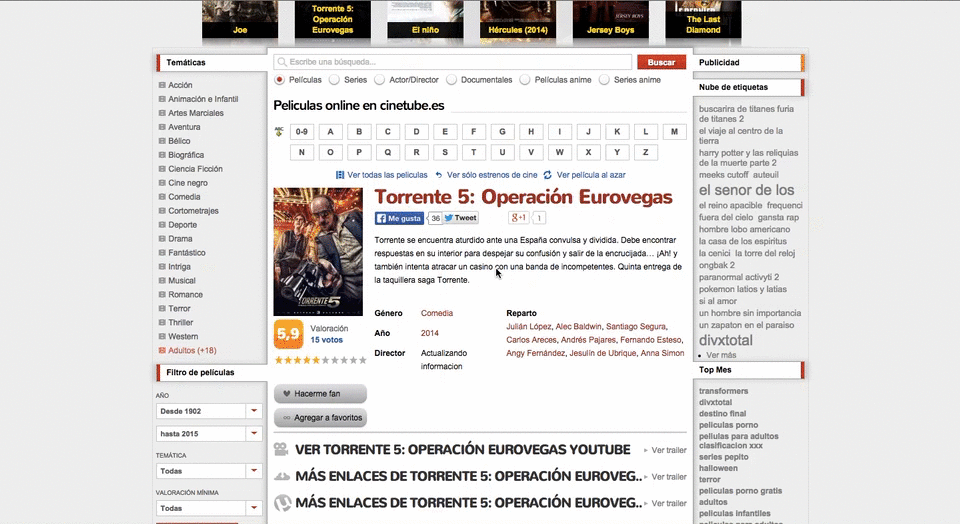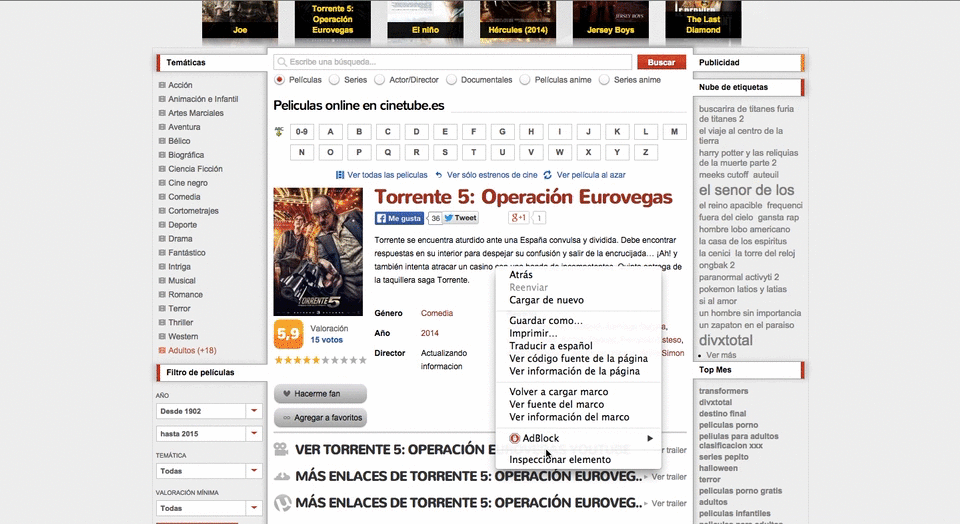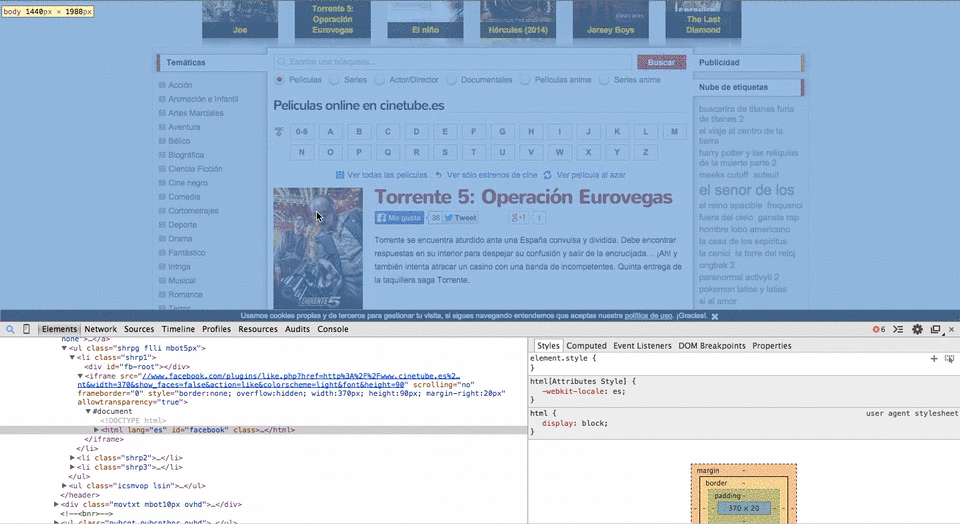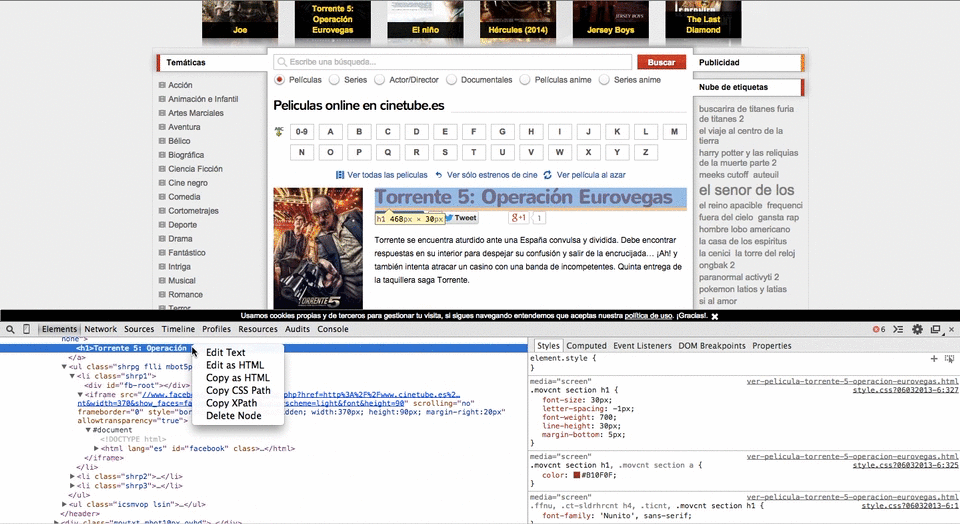
Con el XPATH copiado hacemos CTRL+V en nuestro archivo PHP de la siguiente form
PHP:
$tituloQuery = $xpath->query('//section[2]/section/article/section/header/a/h1/text()');Ahora, para extraer la información de ese XPATH y poder manipularla con mayor facilidad creamos otra variable con el siguiente contenido
PHP:
$titulo = $tituloQuery->item($x)->nodeValue;Repetimos el proceso con todos los elementos que queramos sacar (en este caso -> Genero, Año, Titulo y Portada).
PHP:
// Buscamos cada elemento
$generoQuery = $xpath->query('//section[2]/section/article/section/ul[2]/li/div[1]/div[2]/a/text()');
$anyoQuery = $xpath->query('//section[2]/section/article/section/ul[2]/li/div[2]/div[2]/a/text()');
$tituloQuery = $xpath->query('//section[2]/section/article/section/header/a/h1/text()');
$caratulaQuery = $xpath->query('//section[2]/section/article/aside/div[1]/img/@src');
//Igualamos cada elemento a una variable para manejarlo de una mejor manera.
$genero = $generoQuery->item($x)->nodeValue;
$anyo = $anyoQuery->item($x)->nodeValue;
$titulo = $tituloQuery->item($x)->nodeValue;
$caratula = $caratulaQuery->item($x)->nodeValue;Y ahora ya podemos mostrarlos, insertarlos en una BBDD, editarlos, lo que queramos con ello.
PHP:
//Imprimimos los datos extraidos
echo "<strong>Portada: </strong><img src='".$caratula."' height=120px;></br>";
echo "<strong>Genero: </strong>".$genero."</br>";
echo "<strong>Año: </strong>".$anyo."</br>";
echo "<strong>Titulo: </strong>".$titulo."</br>";El resultado final de nuestro archivo es el siguiente, y con esto sacaremos los datos de una forma fácil y rápida.
PHP:
<?php
// Para que se vean bien los caracteres extraños
header('Content-Type: text/html; charset=utf-8');
// Creamos la conexión con la página
$urlCT = "http://www.cinetube.es/peliculas/comedia/ver-pelicula-torrente-5-operacion-eurovegas.html";
$ch = curl_init($urlCT);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$cl = curl_exec($ch);
$dom = new DOMDocument();
@$dom->loadHTML($cl);
$xpath = new DOMXpath($dom);
// Buscamos cada elemento
$generoQuery = $xpath->query('//section[2]/section/article/section/ul[2]/li/div[1]/div[2]/a/text()');
$anyoQuery = $xpath->query('//section[2]/section/article/section/ul[2]/li/div[2]/div[2]/a/text()');
$tituloQuery = $xpath->query('//section[2]/section/article/section/header/a/h1/text()');
$caratulaQuery = $xpath->query('//section[2]/section/article/aside/div[1]/img/@src');
//Igualamos cada elemento a una variable para manejarlo de una mejor manera.
$genero = $generoQuery->item($x)->nodeValue;
$anyo = $anyoQuery->item($x)->nodeValue;
$titulo = $tituloQuery->item($x)->nodeValue;
$caratula = $caratulaQuery->item($x)->nodeValue;
//Imprimimos los datos extraidos
echo "<strong>Portada: </strong><img src='".$caratula."' height=120px;></br>";
echo "<strong>Genero: </strong>".$genero."</br>";
echo "<strong>Año: </strong>".$anyo."</br>";
echo "<strong>Titulo: </strong>".$titulo."</br>";
?>Resultado:

Sin más, me despido y espero que os sea útil.
Última edición:


